Build your own RL environments w/ Unity ML agents

Why Unity
A couple of months back I started working on a strategy video game based off the Lebanese Civil War. I experimented with a bunch of engines including building my own crappy one and the one I ended up having the most affection towards was Unity.
- Unity has a rich visual interface to create environments and place assets
2. Unity makes it easy to give different game objects various behaviors via the Entity Component System which treats objects as sorts of servers that send messages to other objects to interact with them
3. Lots of assets and useful code on the Asset Store
Why build a simulation? Why not use a benchmark?
At NeurIPS 2016 I had a brief discussion with a prominent Reinforcement Learning researcher where I made the case that new state of the art performance on Atari games was uninteresting and essentially over-fitting massive models on simple games.
I argued that it would be a lot more interesting and productive to develop new kinds of environments that test out new kinds of capabilities 0 → 1 instead of 99.8% → 99.99%.
But the researcher insisted that it would make comparing papers more challenging. I got flashbacks to my SAT days.
Even though I’ve been interested in Games my whole life and Reinforcement Learning my whole professional life, I never realized how big of a connection there was a until a couple of months ago
What is Unity ML agents
In short Unity ML agents is a Unity plugin that lets you hook up your game agents (e.g: enemy AI) to a Reinforcement Learning server which is responsible for 3 things
- Sending the required RL data: states, actions, rewards
- Training the RL model
- Inputting actions back to the game from the model
Reinforcement Learning is a declarative technique for Game AI
Declarative because you don’t need to understand how the RL model works although it does help.
You really only need to do 2 things and Unity ML agents will take care of the rest.
- Encode actions and states
- Set a reward function
So let’s open an example up and see how it all works
Unity ML agents at a glance
The first thing you’ll see in the README is 12 different environments where a couple seem to have several identical agents.
The reason we have simulations with multiple identical agents is that many popular RL algorithms are off policy which is a fancy way of saying that multiple agents can all collect data in the same cache which is called the experience replay buffer. An RL training algorithm would then run on that entire dataset.

Other notable highlights from the README are
- Imitation learning Bootstrap the RL training by a video dataset of you playing the simulation
- Curriculum learning: Where you can chain more complex environments together after an agent excels at a more basic task
- Proximal Policy Optimization & Soft Actor Critic RL algorithms: examples of stable RL algorithms that’ll ensure your agents won’t be too “jerky”. You can download any algorithm you like from Github and integrate it in if you have specific needs
Moving on download Unity , open up the folder \ml-agents\UnitySDK\Assets\ML-Agents\Examples\Template\Scene.unity and then double click on Soccer2 in the projects tab.
Unity ML agents comes with 10 great examples but Soccer2 is both simple and interesting so it’s a great first example.
There are 4 agents in this simulation. 2 red and 2 blue each with a striker and a goalie. They were all created by dragging cube prefabs to the scene viewer and changing a couple of their properties like their size or color.
If we click on the BlueStriker, its properties will pop up to the right
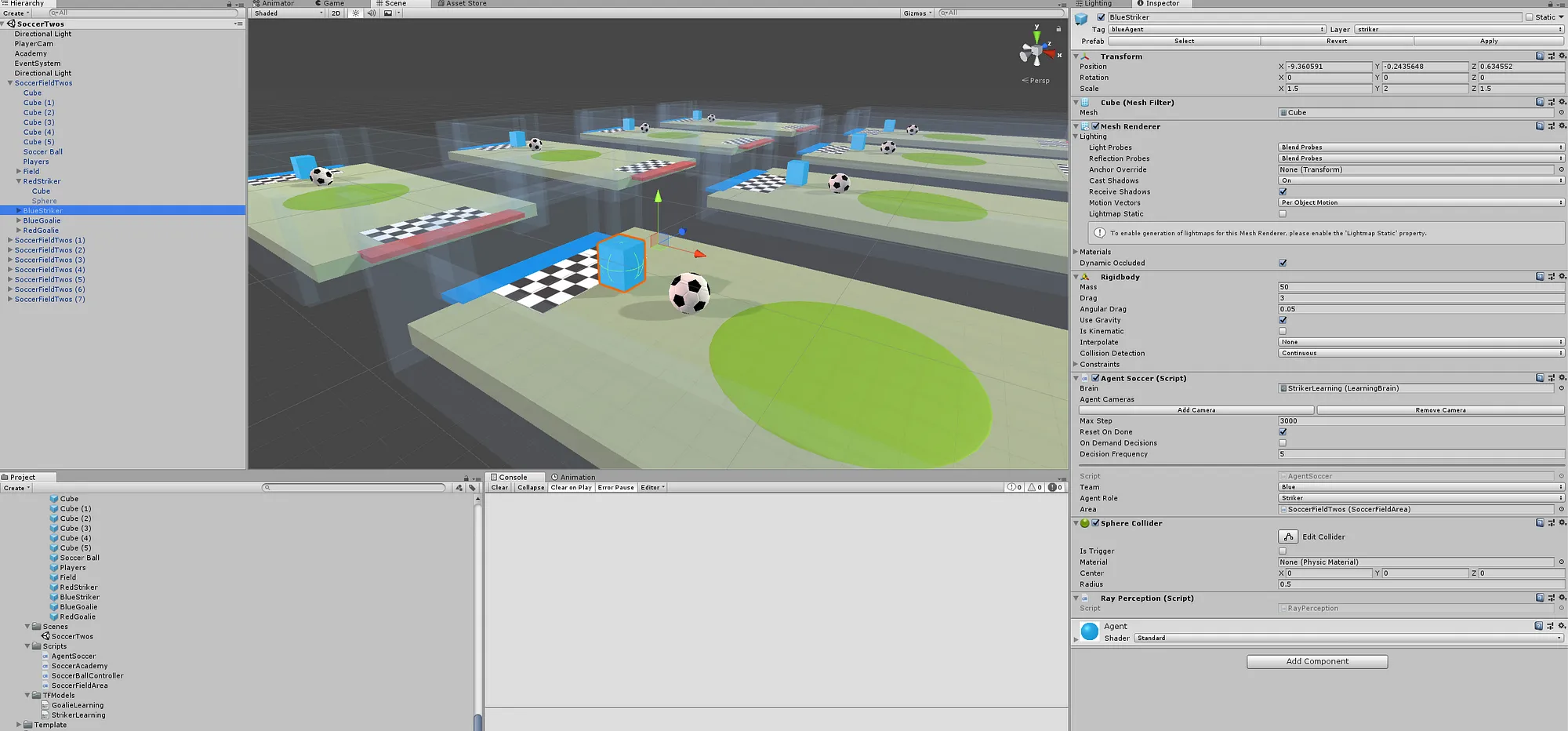
The most important features of the BlueStriker are
- Transform: it’s position, scale and rotation in space
- Mesh: It’s a cube (this could be a humanoid instead)
- RigidBody and Collider: Physics constants associated with the agent
- Script: Looks like there a couple of scripts we need to check out
Code deep dive
There are 4 scripts associated with the soccer environment so let’s go over them 1 by 1.

AgentSoccer
Is responsible for holding all the data that helps instantiate an agent like its team, role and its physical properties like kicking power.

Typically in environments like the ones in Open AI gym, the game state is this abstract thing that’s hard-coded.
However in Unity we can have the agent project rays out of its eyes and simulate a camera sensor attached to the agent. The main ingredient is ray-casts which are also used to detect collisions and project objects on a screen.
The state or observations made by each agent are

Rewards are engineered in an interesting way where we reward goalies for being patient and penalize strikers for being impatient.

Actions are encoded via an enum where goalies can only move in 4 directions and strikers can move in 6. In this example we are explicitly forcing different behaviors for different roles but if we train our RL algorithms long enough we should expect agents to learn that specializing into goalie and striker is beneficial and if it isn’t then we learn a new soccer strategy.

Game specific logic including but not limited to kicking balls

SoccerAcademy
SoccerAcademy is a container for the simulation metadata so mainly holds references to the Brain objects which when attached to a Unity object augments it with the ability to do Reinforcement Learning and other misc stuff like gravitational constant, simulation speed and max number of steps.

SoccerBallController
The SoccerBallController is the logic attached to the ball. When the agents force the ball to cross a goal, the ball checks to see which of the 2 goals its in and increment the score of the right team.

SoccerFieldArea
SoccerFieldArea is a management layer that manages multiple simulations at the same time and updates a GUI so you can easily keep track of which team has the better strategy.
Most importantly it also manages the main reward signal that rewards teams for scoring goals.

Configuring Reinforcement Learning algorithms
There’s one final loose end, how do you set hyper-parameters or configure your Reinforcement Learning algorithm?
One of the key things about RL to remember is that there are already many great implementations of the algorithms out there for free.
Doing RL professionally come to experimenting with different hyper-parameters. A config driven workflow makes this much easier.
Check out ml-agents/config/trainer_config.yaml and you’ll see something that looks like this. Thankfully Unity has already annotated what all these parameters mean.
If you can’t seem to find a good cheat sheet for all the hyper-parameters of an RL algorithm you’re working with, I would strongly suggest you either produce one or use a better documented algorithm.

Specifically for the striker and goalie you’ll notice that there’s hardly any difference (except batch size) between the striker and goalie learning algorithm.

Next steps
You can get pretty far using Unity ML agents for your research projects, video games or DYI robots. My recommendation here is that you do the same thing I did and click around on the various examples.
In particular I really like the Crawler and Reacher example because they show you how to model a skeleton using Unity and then have it reach certain goals.


There’s also a bunch of companies out there building self driving car simulators or robot simulators so if you’re clever about it you can make money doing this kind of stuff too.
For next time I wanna talk about something slightly different: AlphaZero which is a general purpose algorithm which can solve most full information board games out there.
So stick around if you wanna learn more about turn based strategy games, Monte Carlo Tree Search and Game theory!

